- Home
- Latest poker news
- GTO Wizard AI Crushed LLM in Poker Heads-ups
GTO Wizard AI Crushed LLM in Poker Heads-ups
GTO Wizard ran a showcase experiment to test how well modern AI handles poker. Their agent played a series of heads-up matches against leading language models, from GPT-5.4 to Kimi K2.5, and the outcome was clear: every model was decisively outplayed.
5,000 hands with no chance for LLM
AI is steadily expanding into everyday use—from search and programming to advanced analytics—so it was only natural to evaluate its performance in games of incomplete information, where strategy, mathematics, and adaptation are essential.
The first results, published in late 2025, showed that universal models could compete but were still far from consistently delivering strong play. And recently, a new experiment was conducted, in which LLMs were no longer playing against each other.
GTO Wizard* published the results of a large-scale benchmark: their specialized AI played against all major language models. The results were unambiguous: the GTO Wizard AI confidently outperformed all competitors.
*GTO Wizard is a team of developers who created a GTO-based poker training platform and a cloud-based solver.
How the GTO Wizard benchmark was carried out
The experiment involved all major models: various versions of GPT, Claude, Gemini, Grok, and Kimi.
It should be noted that the conditions were the same for all participants:
- ♥️ No-Limit Texas Hold'em.
- 💰 Deep stacks of 200bb.
- ⚔️ 5,000 hands played in heads-up.
- 🤖 A unified evaluation methodology using AIVAT— a system that reduces the impact of variance by approximately tenfold and measures decision quality from a GTO standpoint, rather than relying on raw table results.
One key detail: the developers didn’t clarify whether rake was factored into the results. However, even when recalculated with a 5% rake, the overall outcome of the match remains unchanged.
Results: complete rupture
The result was clear: all models were significantly negative.
- GPT-5.3 XHigh Reasoning showed the best result – minus 16 bb/100. For context, strong professionals in heads-up play against other players maintain a level of approximately +4 bb/100 (this is the benchmark used by GTO Wizard).
- GPT-5.4 Nano (No Reasoning) showed the worst results – minus 189.7 bb/100.
| Rank | Model | Developer | Luck-adjusted win rate (bb/100) | Std. dev |
|---|---|---|---|---|
| 1 | GPT-5.3 (XHigh Reasoning) | OpenAI | -16.0 | ±3.0 |
| 2 | Marvel | MIT | -14.0 | ±4.7 |
| 3 | GPT-5.4 (XHigh Reasoning) | OpenAI | -17.8 | ±3.7 |
| 4 | GPT-5.3 (High Reasoning) | OpenAI | -18.2 | ±3.9 |
| 5 | Claude Opus 4.6 | Anthropic | -20.4 | ±4.4 |
| 6 | Gemini 3.1 Pro | ~-30.8 | — | |
| 7 | Kimi K2.5 | Moonshot AI | ~-40 to -50 | — |
| 8 | Grok 4 | xAI | ~-60 | — |
| 9 | GPT-4o / older baselines | OpenAI | < -100 | — |
| 10 | GPT-5.4 Nano (No Reasoning) | OpenAI | -189.7 | — |
Why LLM lost
After analyzing hands, the GTO Wizard team identified four systemic factors that prevent universal models from playing poker at a high level:
- 🕶️ Hidden information: the model can’t see the opponent’s cards and has to rely entirely on probabilities.
- ⚖️ Range balancing: poker presents thousands of situations where even small strategic imbalances can be exploited.
- 🧠 Long-term planning: each decision affects later streets, and errors compound into EV losses.
- ❓Modeling opponent behavior under uncertainty: this demands a strong probabilistic model, which LLMs do not explicitly provide.
A fundamental problem was also identified: even advanced models misinterpret their own cards in approximately 2% of cases, confusing suits and combinations. In poker, such errors instantly translate into negative EV.
What's the power of GTO Wizard AI?
The developers emphasize that GTO Wizard AI plays near Nash equilibrium, making it highly resistant to exploitation.
The benchmark they use is around 4 bb/100 as the level of elite players against the field. However, against a specialized AI, even players of this level would still lose, according to the model’s logic.
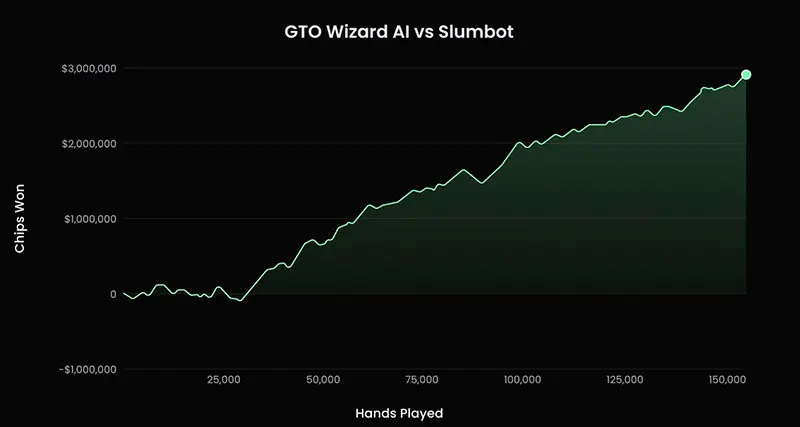
The technical foundation of the system is Ruse AI, developed by Canadian researchers Philippe Birdsell and Marc-Antoine Provost. In 2023, it beat Slumbot, one of the strongest public poker bots, with a score of +19.4 bb/100 over 150,000 hands. The project was later integrated into the GTO Wizard ecosystem and became the basis for the current AI engine.
The experiment format itself is also worth considering. GTO Wizard has made the benchmark public: any developer can connect their agent via the API and play the same HU matches. This effectively turns the system into a single standard for evaluating poker AI and provides direct comparisons between different models under the same conditions.
GTO Wizard vs. LLM: the main conclusion
The results of the experiment are unambiguous: general-purpose language models still cannot compete with specialized poker agents, even in heads-up play.
The gap between the approaches proved to be systemic rather than incidental. It clearly demonstrates the current limits of capabilities: general-purpose intelligence versus highly specialized optimization.
In this context, poker isn’t just a game, but a rigorous benchmark of the capabilities and boundaries of modern LLMs.
During the 2026 WSOP Main Event broadcasts, ESPN's cameras frequently focused on Alex Foxen's tab...
The Day 2 action of the second edition of Hellmuth’s Home Game has just been released by Po...
Yes, online poker remains profitable in 2026. But if you're looking for "easy money", like it was...
Poker pro and commentator Derek Kwan published an article on X in which he mentioned that live to...